Огляд методів
Шукаючи в Інтернеті, я натрапив на різні рішення. Я можу згрупувати їх за трьома підходами:
- наївні , що використовують
file()функцію PHP;
- обман тих, хто запускає
tailкоманду в системі;
- могутні , які із задоволенням стрибають навколо відкритого файлу за допомогою
fseek().
Врешті-решт я вибрав (або написав) п’ять рішень, наївне , шахрайське та три могутні .
- Найкоротше наївне рішення з використанням вбудованих функцій масиву.
- Можливо тільки рішення , засноване на
tail команду , яка має трохи більшу проблему: вона не запускається , якщоtail немає, то є на НЕ-Unix (Windows) або на обмежених умовах , які не дозволяють системні функції.
- Рішення, в якому одиночні байти зчитуються з кінця файлу, шукаючи (та підраховуючи) символи нового рядка, знайдено тут .
- Багатобайтові буферний розчин , оптимізований для великих файлів, знайшов
тут .
- Трохи модифікована версія рішення №4, в якій довжина буфера є динамічною, визначається відповідно до кількості рядків для отримання.
Всі рішення працюють . У тому сенсі, що вони повертають очікуваний результат з будь-якого файлу та для будь-якої кількості рядків, про які ми просимо (за винятком рішення №1, яке може порушити обмеження пам’яті PHP у разі великих файлів, нічого не повертаючи). Але який з них краще?
Тести продуктивності
Щоб відповісти на запитання, я запускаю тести. Ось як це робиться, чи не так?
Я підготував зразок файлу розміром 100 КБ, що поєднує різні файли, знайдені в моєму /var/logкаталозі. Потім я написав PHP-скрипт, який використовує кожне з п’яти рішень для отримання 1, 2, .., 10, 20, ... 100, 200, ..., 1000 рядків з кінця файлу. Кожен окремий тест повторюється десять разів (це приблизно 5 × 28 × 10 = 1400 тестів), вимірюючи середній час, що минув у мікросекундах.
Я запускаю сценарій на своїй локальній машині розробки (Xubuntu 12.04, PHP 5.3.10, двоядерний процесор 2,70 ГГц, 2 ГБ оперативної пам'яті) за допомогою інтерпретатора командного рядка PHP. Ось результати:
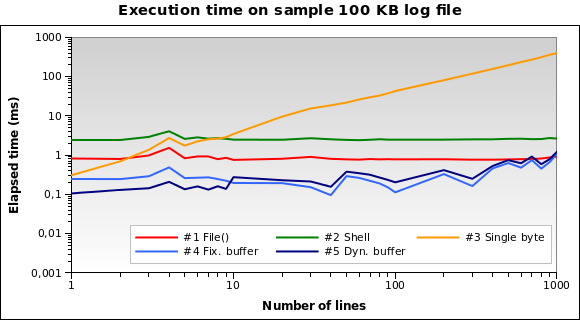
Рішення №1 та №2 здаються гіршими. Рішення No3 добре лише тоді, коли нам потрібно прочитати кілька рядків. Рішення №4 та №5 здаються найкращими.
Зверніть увагу, як динамічний розмір буфера може оптимізувати алгоритм: час виконання трохи менший для кількох рядків через зменшений буфер.
Давайте спробуємо з більшим файлом. Що робити, якщо нам доведеться прочитати файл журналу 10 МБ ?
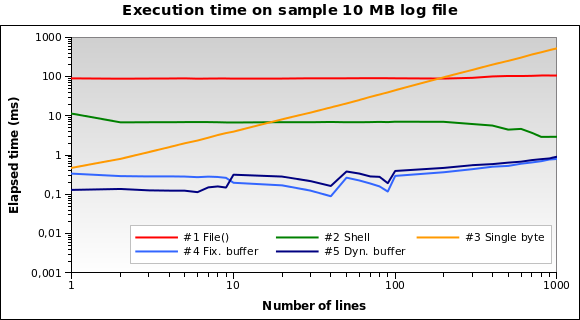
Зараз рішення №1 набагато гірше: насправді завантаження всього 10-МБ файлу в пам’ять - це не чудова ідея. Я запускаю тести також на файлах розміром 1 МБ і 100 МБ, і це практично та ж ситуація.
А для крихітних файлів журналів? Ось графік файлу 10 КБ :
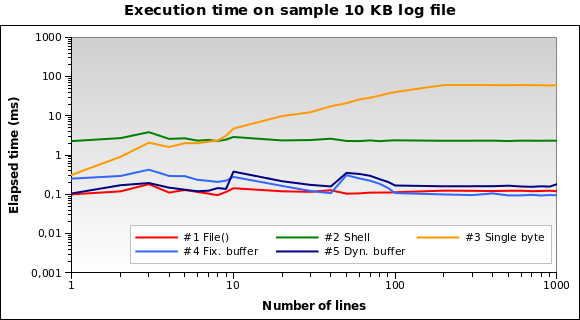
Рішення No1 зараз найкраще! Завантаження 10 Кб в пам’ять для PHP не є великою проблемою. Також №4 та №5 мають хороші результати. Однак це крайній випадок: журнал 10 КБ означає щось на зразок 150/200 рядків ...
Ви можете завантажити всі мої тестові файли, джерела та результати
тут .
Заключні думки
Рішення №5 настійно рекомендується для загального використання: чудово працює з будь-яким розміром файлу і особливо добре працює при читанні кількох рядків.
Уникайте рішення №1, якщо вам слід прочитати файли розміром більше 10 КБ.
Рішення №2
та №3
- не найкращі для кожного тесту, який я виконую: №2 ніколи не виконується менше ніж за 2 мс, а на №3 сильно впливає кількість запитаних рядків (працює цілком добре лише з 1 або 2 рядками ).
$file = file('filename.txt'); echo $file[count($file) - 1];