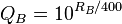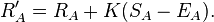Більшість наївних підходів до проблеми мають кілька серйозних проблем. Найгірше те, як bash.org та qdb.us відображають котирування - користувачі можуть проголосувати за котирування вгору (+1) або вниз (-1), а список найкращих котирувань сортується за загальним чистим балом. Це страждає від жахливого часового упередження - старі цитати накопичили величезну кількість позитивних голосів завдяки простому довголіття, навіть якщо вони лише незначно жартівливі. Цей алгоритм може мати сенс, якби жарти ставали веселішими, коли вони старіли, але - повірте, вони цього не роблять.
Існують різні спроби це виправити - дивлячись на кількість позитивних голосів за певний період, зважуючи нещодавні голоси, запроваджуючи систему затухання для старих голосів, обчислюючи відношення позитивних та негативних голосів тощо. Більшість страждають від інших недоліків.
Я вважаю, що найкращим рішенням є те, яке використовують веб-сайти The Funniest The Cutest , The Fairest і Best Thing - модифікована система голосування Condorcet :
Система надає кожному число, виходячи з того, з чим стикалася, скільки відсотків із них вона зазвичай перемагає. Отже, кожен отримує відсотковий бал NumberOfThingsIBeat / (NumberOfThingsIBeat + NumberOfThingsThatBeatMe). Крім того, речі заборонені до верхнього списку, поки їх не порівняють з розумним відсотком від набору.
Якщо у наборі є переможець Condorcet, цей метод знайде його. Оскільки це малоймовірно, враховуючи статистичну природу, він знаходить того, хто є найближчим до переможця Кондорсе.
Для отримання додаткової інформації щодо впровадження таких систем корисною буде сторінка Вікіпедії з рейтинговими парами .
Алгоритм вимагає, щоб люди порівнювали два об'єкти (ваш варіант "вибрати" або "B"), але, чесно кажучи, це добре. Я вважаю, що в теорії прийняття рішень дуже добре прийнято, що люди набагато краще порівнюють два об'єкти, ніж вони мають абстрактний рейтинг. Мільйони років еволюції роблять нас добрими в збиранні найкращого яблука з дерева, але страшним у вирішенні того, наскільки ті яблука, які ми зібрали, відповідають справжній платонічній формі яблуні. (Це, до речі, чому процес аналітичної ієрархії такий витончений ... але це трохи відходить від теми.)
Останнє, що слід сказати, полягає в тому, що SO використовує алгоритм для пошуку найкращих відповідей, який дуже схожий на алгоритм bash.org для пошуку найкращої цитати. Тут це добре працює, але там жахливо не вдається - багато в чому тому, що тут, швидше за все, буде відредагована стара, високо оцінена, але тепер застаріла відповідь. bash.org не дозволяє редагувати, і незрозуміло, як Ви хотіли б навіть редагувати десятилітні давно жарти про давно встановлені меми в Інтернеті, навіть якби могли ... У будь-якому випадку, я хочу сказати, що зазвичай правильний алгоритм залежить від деталей вашої проблеми. :-)