У мене це питання було місяцями. Схоже, ми просто розумно відгадали софтмакс як функцію виводу, а потім інтерпретували вхід у софтмакс як імовірності журналу. Як ви сказали, чому б просто не нормалізувати всі результати, поділивши їх суму? Відповідь я знайшов у книзі « Глибоке навчання» Goodfellow, Bengio та Courville (2016) у розділі 6.2.2.
Скажімо, наш останній прихований шар дає нам z як активацію. Тоді софтмакс визначається як

Дуже коротке пояснення
Exp у функції softmax приблизно скасовує журнал у перехресній ентропії втрати, спричиняючи, що втрата буде приблизно лінійною в z_i. Це призводить до приблизно постійного градієнта, коли модель помиляється, що дозволяє їй швидко виправитись. Таким чином, неправильна насичена софтмакс не викликає зникаючого градієнта.
Коротке пояснення
Найпопулярніший метод тренування нейронної мережі - це оцінка максимальної вірогідності. Ми оцінюємо параметри тети таким чином, щоб максимально збільшити ймовірність даних про навчання (розміром m). Оскільки ймовірність усього набору даних тренінгу є результатом ймовірності кожного зразка, простіше максимально збільшити ймовірність журналу набору даних, а отже, імовірність журналу кожного зразка, індексовану k:
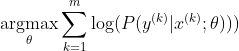
Тепер ми зосередимось лише на softmax тут із уже заданим z, тому ми можемо замінити
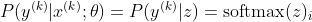
при цьому я є правильним класом k-го зразка. Тепер ми бачимо, що, приймаючи логарифм софтмакс, для обчислення ймовірності вибірки журналу, ми отримуємо:
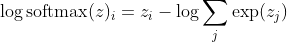
, що для великих відмінностей z приблизно дорівнює
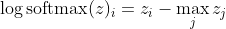
Спочатку ми бачимо тут лінійну складову z_i. По-друге, ми можемо вивчити поведінку max (z) для двох випадків:
- Якщо модель правильна, то max (z) буде z_i. Таким чином, асимптоти часоподібної ймовірності дорівнюють нулю (тобто ймовірність 1) зі зростаючою різницею між z_i та іншими записами в z.
- Якщо модель невірна, то max (z) буде деяким іншим z_j> z_i. Отже, додавання z_i не повністю скасовує вихід -z_j, а ймовірність журналу приблизно (z_i - z_j). Це чітко говорить про модель, що потрібно зробити, щоб збільшити ймовірність журналу: збільшити z_i та зменшити z_j.
Ми бачимо, що в загальній ймовірності журналу будуть домінувати зразки, де модель неправильна. Крім того, навіть якщо модель справді неправильна, що призводить до насиченого софтмаксу, функція втрат не насичує. Це приблизно лінійно в z_j, це означає, що ми маємо приблизно постійний градієнт. Це дозволяє моделі швидко виправити себе. Зауважте, що це не стосується, наприклад, середньої помилки в квадраті.
Довге пояснення
Якщо софтмакс все ж здається вам довільним вибором, ви можете поглянути на виправдання використання сигмоїди в логістичній регресії:
Чому сигмоїдна функція замість чого-небудь іншого?
Софтмакс - це узагальнення сигмоїди для задач багатокласу, виправданих аналогічно.



