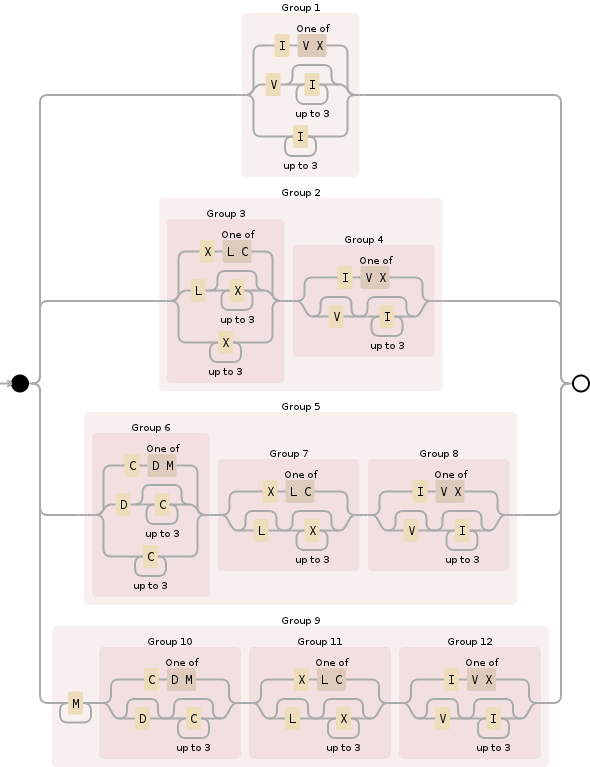
Для цього можна використовувати наступний регулярний вираз:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
Розбивши його, M{0,4}вказує розділ тисячі і в основному обмежує його між 0і 4000. Це порівняно просто:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
Звичайно, ви можете використовувати щось на зразок, M*щоб дозволити будь-яку кількість (включаючи нуль) тисяч, якщо ви хочете дозволити більші числа.
Далі (CM|CD|D?C{0,3}), трохи складніше, це для сотні розділів і охоплює всі можливості:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
По-третє, (XC|XL|L?X{0,3})дотримуйтесь тих же правил, що і в попередньому розділі, але для десятків місце:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
І, нарешті, (IX|IV|V?I{0,3})є розділ одиниць, обробка 0через 9та також схожий на попередні дві секцій (римські цифри, незважаючи на їх позірну дивина, слідують деякими логічними правилами , як тільки ви з'ясувати , що вони є):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
Просто майте на увазі, що цей регулярний вираз також буде відповідати порожній рядку. Якщо ви цього не хочете (і ваш двигун регулярного випромінювання досить сучасний), ви можете використовувати позитивні перспективи та перспективи:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(інша альтернатива полягає у тому, щоб попередньо перевірити, чи довжина не дорівнює нулю).