Це дві різні показники для оцінки продуктивності вашої моделі, яка зазвичай використовується на різних етапах.
Втрати часто використовуються в тренувальному процесі, щоб знайти "найкращі" значення параметрів для вашої моделі (наприклад, ваги в нейронній мережі). Це те, що ви намагаєтеся оптимізувати в тренуванні, оновлюючи ваги.
Точність більше з прикладної точки зору. Виявивши оптимізовані параметри вище, ви використовуєте ці показники, щоб оцінити, наскільки точний прогноз вашої моделі порівняно з справжніми даними.
Скористаємося прикладом класифікації іграшок. Ви хочете передбачити стать за вагою і зростом. У вас є 3 дані, вони такі: (0 підстав для чоловіків, 1 підставка для жінок)
y1 = 0, x1_w = 50кг, x2_h = 160см;
y2 = 0, x2_w = 60кг, x2_h = 170см;
y3 = 1, x3_w = 55кг, x3_h = 175см;
Ви використовуєте просту модель логістичної регресії, яка y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
Як ви знаходите b1 і b2? спершу ви визначаєте збитки і використовуєте метод оптимізації, щоб мінімізувати втрати ітераційним шляхом, оновивши b1 і b2.
У нашому прикладі типовою втратою для цієї проблеми бінарної класифікації може бути: (перед знаком підсумовування слід додати знак мінус)

Ми не знаємо, якими повинні бути b1 і b2. Зробимо випадкову здогадку, скажімо, b1 = 0,1 і b2 = -0,03. Тоді яка наша втрата зараз?
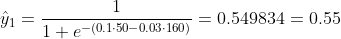
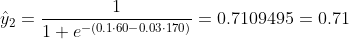
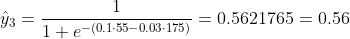
тому втрата є
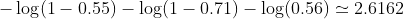
Тоді алгоритм навчання (наприклад, спуск градієнта) знайде спосіб оновити b1 і b2, щоб зменшити втрати.
Що робити, якщо b1 = 0,1 і b2 = -0,03 є кінцевими b1 і b2 (вихід із градієнтного спуску), яка точність зараз?
Припустимо, якщо y_hat> = 0,5, ми вирішимо, що наше передбачення жіноче (1). інакше було б 0. Тому наш алгоритм прогнозує y1 = 1, y2 = 1 і y3 = 1. Яка наша точність? Ми робимо неправильне передбачення на y1 і y2 і робимо правильне на y3. Тож тепер наша точність становить 1/3 = 33,33%
PS: У відповіді Аміра , зворотне поширення вважається оптимізаційним методом в NN. Я думаю, це було б розцінено як спосіб знайти градієнт для ваг у NN. Поширеними методами оптимізації в NN є GradientDescent та Adam.
