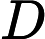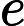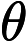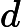Знайти відмінності можна за допомогою перегляду моделей. Давайте спочатку розглянемо розріджене кодування.
Рідке кодування
Рідке кодування мінімізує об'єктивний
де - матриця основ, H - матриця кодів і - матриця даних, які ми хочемо представити. реалізує торгівлю між розрідженістю та реконструкцією. Зауважимо, що якщо нам задано , то оцінка є легкою через найменші квадрати. WXλHW




























На початку, ми не маємо однако. Тим НЕ менше, багато алгоритми існують , які можуть вирішити мета вище по відношенню до . Власне, саме так ми робимо висновок: нам потрібно вирішити оптимізаційну задачу, якщо ми хочемо знати що належить до небаченого .Hx

Авто кодування
Авто-кодери - це сімейство непідконтрольних нейронних мереж. Їх досить багато, наприклад, глибокі автокодери або такі, що мають різні прийоми регуляризації - наприклад, деноізуючі, контрактивні, рідкісні. Навіть існують імовірнісні такі, як генеративні стохастичні мережі або варіаційний авто кодер. Найбільш абстрактною їх формою є
але зараз ми підемо разом із набагато простішою:
де - нелінійна функція, така як логістична сигмоїда .L ae = | | W σ ( W T X ) - X | | 2 σ σ ( x ) = 1









Схожість
Зверніть увагу, що виглядає майже як коли ми встановимо . Різниця обох полягає в тому, що i) автоматичні кодери не заохочують рідкість у загальному вигляді; ii) автокодер використовує модель для пошуку кодів, тоді як розріджене кодування робить це за допомогою оптимізації.L a e H=σ( W T X)




Для даних зображення, природно , введені авто кодеров і рідкісних кодувань , як правило, дають дуже схожий . Однак автоматичні кодери набагато ефективніші та легко узагальнені на значно складніші моделі. Наприклад, декодер може бути сильно нелінійним, наприклад, глибока нейронна мережа. Крім того, одна не прив’язана до квадратних втрат (від яких залежить оцінка для .)W L s c
Крім того, різні методи регуляризації дають уявлення з різною характеристикою. Позначені автоматичні кодери також показали, що вони еквівалентні певній формі УЗМ тощо.
Але чому?
Якщо ви хочете вирішити проблему передбачення, вам не знадобляться автоматичні кодери, якщо у вас є лише невеликі мічені дані та безліч мічених даних. Тоді вам, як правило, буде краще тренувати глибокий автокодер і встановлювати лінійний SVM, а не тренувати глибоку нейронну сітку.
Однак вони є дуже потужними моделями для захоплення характеристик розподілів. Це нечітко, але дослідження, що перетворюють це на важкі статистичні факти, наразі проводяться. Глибоко приховані гауссові моделі, такі як кодери з різноманітним авто або генераторні стохастичні мережі, є досить цікавими способами отримання автоматичних кодерів, які, очевидно, оцінюють базовий розподіл даних.