Це питання виникає з моєї фактичної плутанини щодо того, як вирішити, чи достатньо хороша логістична модель. У мене є моделі, які використовують стан пар індивідуальний проект через два роки після їх формування як залежної змінної. Результат успішний (1) чи ні (0). У мене є незалежні змінні, виміряні в момент утворення пар. Моя мета - перевірити, чи може змінна, за якою я вважав, впливати на успіх пар, впливатиме на цей успіх, контролюючи інші потенційні впливи. У моделях змінна інтерес є значною.
Моделі були оцінені за допомогою glm()функції в R. Для оцінки якості моделей, я зробив кілька речей: glm()дає вам residual deviance, то AICі BICза замовчуванням. Крім того, я підрахував коефіцієнт похибки моделі та побудував схему залишків, породжених у кошику.
- Повна модель має менший залишковий відхилення, AIC та BIC, ніж інші моделі, які я оцінив (і які вкладені в повну модель), що змушує мене думати, що ця модель "краща", ніж інші.
- Частота помилок моделі досить низька, IMHO (як у Gelman and Hill, 2007, с. 99 ):,
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)приблизно 20%.
Все йде нормально. Але коли я розміщую залишкову залишку (знову слідуючи порадам Гельмана та Хілла), значна частина бункерів випадає за межі 95% ІС:
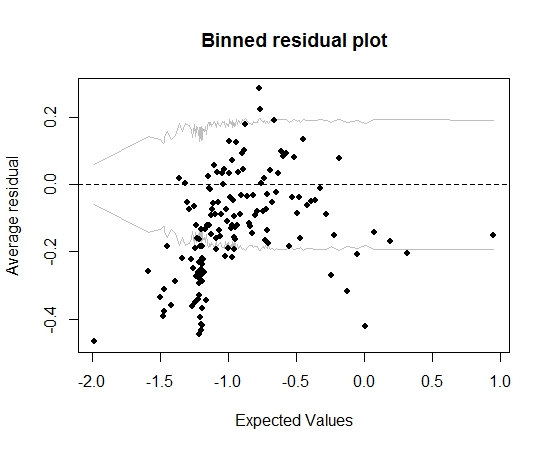
Цей сюжет спонукає мене думати, що в моделі щось зовсім не так. Чи повинно це призвести до того, щоб я скинув модель? Чи слід визнати, що модель недосконала, але зберігати її та інтерпретувати ефект змінної, що цікавить? Я пограбував, виключаючи змінні по черзі, а також деяку трансформацію, не вдосконалюючи при цьому дійсно покращений графік залишків.
Редагувати:
- На даний момент модель має десяток прогнозів і 5 ефектів взаємодії.
- Пари "відносно" незалежні одна від одної в тому сенсі, що всі вони формуються за короткий проміжок часу (але не строго кажучи, все одночасно) і є багато проектів (13 к) і багато людей (19 к ), тому неабияку частку проектів приєднує лише одна людина (налічується близько 20000 пар).