У своїй роботі по автоассоціатор для тексту класифікації Хінтон і Салахутдинов показав сюжет , отриманий на 2-мірної LSA (який тісно пов'язаний з PCA) 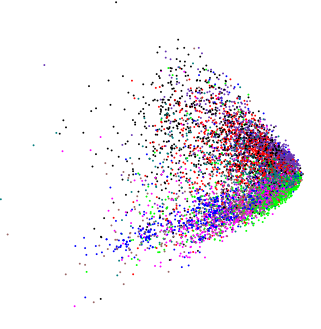 .
.
Застосовуючи PCA до абсолютно різних злегка високих розмірних даних, я отримав подібний зовнішній вигляд:  (за винятком цього випадку я дуже хотів знати, чи є якась внутрішня структура).
(за винятком цього випадку я дуже хотів знати, чи є якась внутрішня структура).
Якщо ми подаємо випадкові дані в PCA, ми отримаємо диск у формі диска, тому ця форма клиноподібної форми не є випадковою. Чи означає це щось саме по собі?
6
Я припускаю, що всі змінні є позитивними (або негативними) та безперервними? Якщо так, краї клина - це лише точки, за якими дані ставали б 0 / мінус. Крім того, ви можете отримати ту саму схему, яку ви показуєте, за допомогою позитивних змінних праворуч змінних; спостереження збиті внизу. Якби у вас були позитивні однакові випадкові величини, ви побачили (повернутий) квадрат. Отже, такі моделі, як показана вами, є лише обмеженнями в даних. Інші шаблони можуть з'являтися, як підкова, але вони не пов'язані з обмеженнями в діапазонах змінних.
—
Гевін Сімпсон
@GavinSimpson Це значно більше, ніж коментар. Чому б не розширити це на відповідь?
—
Майк Хантер
Я запитав своїх дітей (3 та 4 роки), що їм нагадують ці малюнки, і вони сказали, що це риба. То, можливо, "рибоподібна форма"?
—
амеба
@GavinSimpson, дякую! В обох випадках змінні дійсно є негативними, бот також в обох випадках цілим числом. Це щось змінює?
—
macleginn







