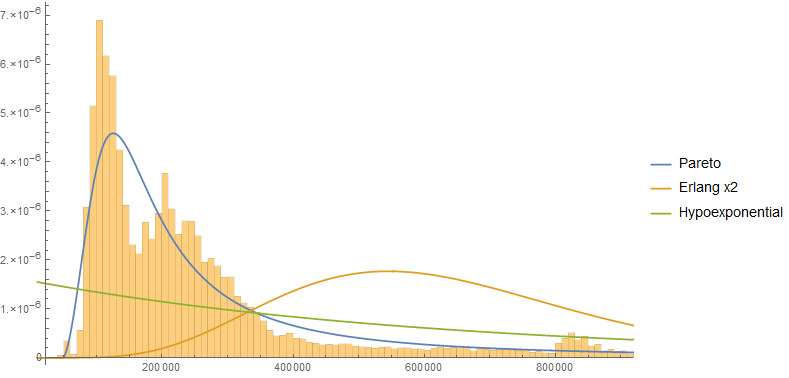
У мене є сервлет-додаток, в якому я вимірюю час, необхідний для виконання кожного запиту до цього сервлета. Я вже обчислюю просту статистику, як середнє та максимальне; Однак я хотів би зробити ще більш складний аналіз, і для цього я вважаю, що мені потрібно правильно моделювати ці часи реакції.
Безумовно, я говорю, часи відгуку йдуть за відомим розповсюдженням, і є вагомі підстави вважати, що розподіл - це правильна модель. Однак я не знаю, яким має бути цей розподіл.
Зрозуміло, що для журналу звичайно і гамма, ви можете створити будь-який тип даних реального часу відповіді. Хтось має уявлення про те, який розподіл повинен тривати час реакції?