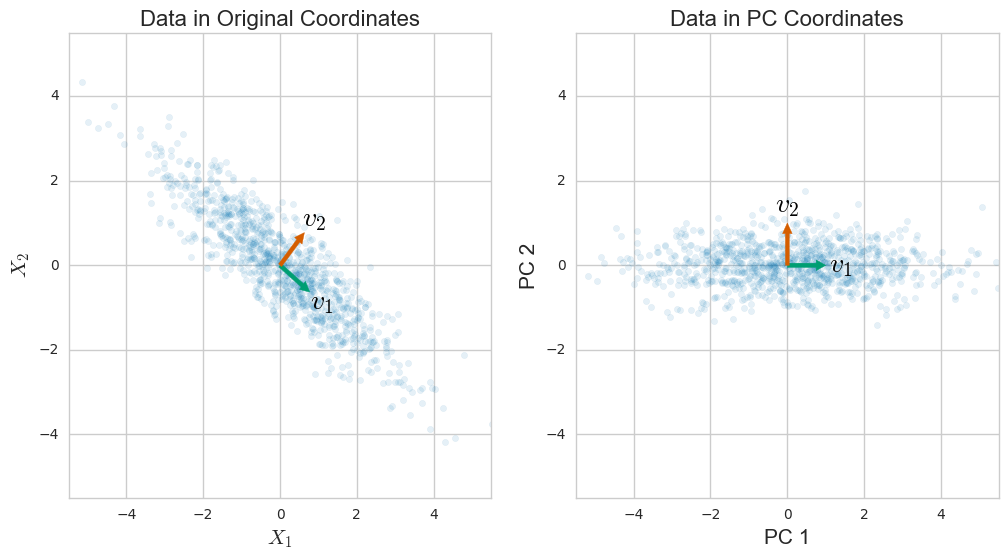
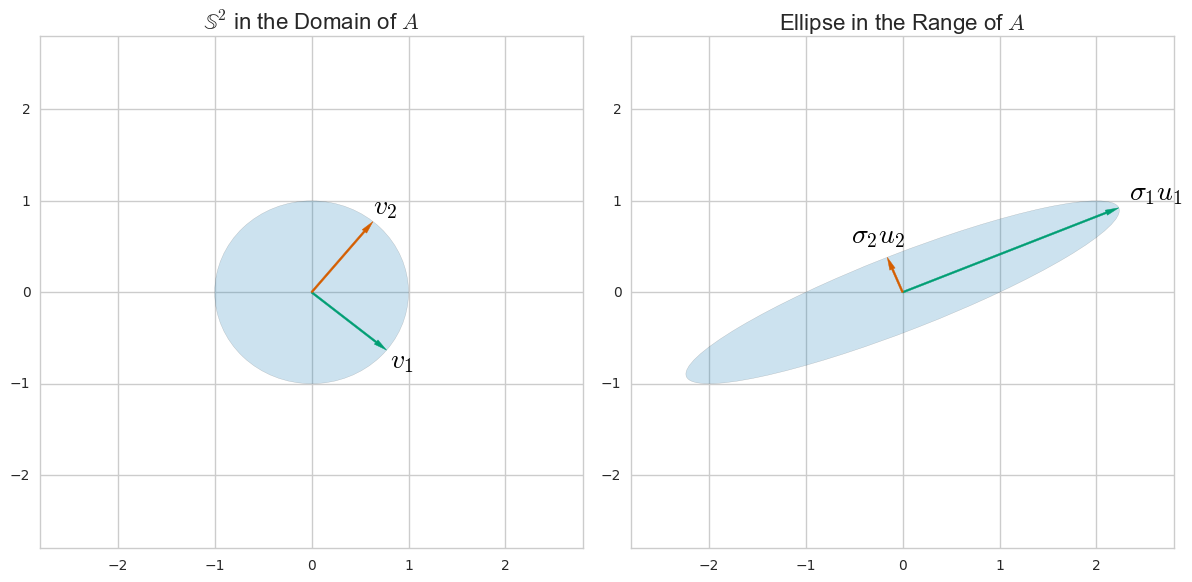
Аналіз основних компонентів (PCA) зазвичай пояснюється шляхом власного розкладання коваріаційної матриці. Тим НЕ менше, він також може бути виконаний з допомогою сингулярного розкладання (SVD) матриць даних . Як це працює? Який зв’язок між цими двома підходами? Який взаємозв'язок між SVD та PCA?
Або іншими словами, як використовувати SVD матриці даних для виконання зменшення розмірності?
8
Я написав це запитання у стилі FAQ разом зі своєю власною відповіддю, оскільки його часто задають у різних формах, але немає канонічної нитки, і тому закрити дублікати складно. Будь ласка, надайте мета коментарі в цій супровідній метапотоці .
—
амеба
На додаток до чудової та детальної відповіді амеби та її подальших посилань, я можу порекомендувати перевірити це , коли PCA розглядається поруч з деякими іншими методами на основі SVD. У дискусії представлена алгебра, майже ідентична амебі, з незначною різницею, що мова, описана PCA, йде про розкладання svd [абоX/ √ ] замість X- що просто зручно, оскільки це стосується PCA, виконаного за допомогою ейгендекомпозиції матриці коваріації.
—
ttnphns
PCA - це особливий випадок SVD. PCA потребує нормалізованих даних, в ідеалі однаковий блок. Матриця nxn в PCA.
—
Орвар Корвар
@OrvarKorvar: Про яку матрицю nxn ви говорите?
—
Cbhihe